4 tipos de visión por computadora que deberías conocer (códigos incluídos)
Descubre los 4 desafíos típicos de visión por computadora y como resolverlos con código de ejemplo. La tecnología que permite a las máquinas dar sentido al mundo que los rodea 🤖👁️


Cerca del 2010 los investigadores de visión artificial pensaban que hacer que una computadora distinguiera un gato de un perro sería casi imposible.
Luego, el 2012 llegó AlexNet, una red neuronal convolucional de 8 capas de profundidad que rompió record en el desafío de reconocimiento visual de imágenes por computadora ImageNet Large Scale Visual Recognition Challenge.
Esta red definiría lo que hoy conocemos como Redes Neuronales Profundas.
Y hoy podemos diferenciar un gato de un perro con un nivel superior al 99 % de precisión.
La visión artificial paso de ser algoritmos específicos para cada problema a ser una red neuronal que podía resolver varias clasificaciones a la vez.
Hoy queremos hablar de cuatro diferentes problemas en visión artificial y una tecnología que resuelve los cuatro.
4 problemas típicos de visión por computadora
La visión por computadora es dar sentido a las imágenes, identificando el contenido de lo que hay en una imagen o dando sentido a un video.
En orden de menor a mayor complejidad, podríamos catalogar los problemas en 4 categorías:
- Clasificación de imágenes: Qué es lo que veo en la imagen
- Detección de objetos: Donde están distintos objetos en la imagen
- Segmentación semántica: Qué forma tienen distintos objetos en la imagen
- Estimación de puntos clave: Que pose tienen las distintas formas dentro de la imagen
Para poner en práctica estos conceptos, vamos a usar uno de los modelos más populares de visión por computadora. Su nombre es YOLO, y en su versión 8 permite resolver los 4 problemas.
Si quieres saltar directo al código, te comparto el Google Colab con los ejemplos de esta publicación.


Clasificación de imágenes
La clasificación de imágenes es uno de los problemas más sencillos de visión por computadora. Busca responder a la pregunta ¿Qué veo en la imagen?
Dependiendo de la complejidad del problema, podríamos usar un algoritmo de clasificación que asigna solo una o bien varias categorías a la imagen.
La clasificación de imágenes es útil cuando sólo necesitas saber a qué clase pertenece una imagen y no necesitas saber dónde se encuentran los objetos de esa clase ni cuál es su forma exacta.
Puede parecer que en un contexto real no hay espacio para algo tan simple, pero imagina como caso de uso una línea de producción con distintas categorías de producto. Un clasificador de imagen podría informar qué producto está viendo y tomar alguna decisión en base a esta información.
Ahora vamos al código. Para este ejemplo, nuestra imagen de prueba será la siguiente:
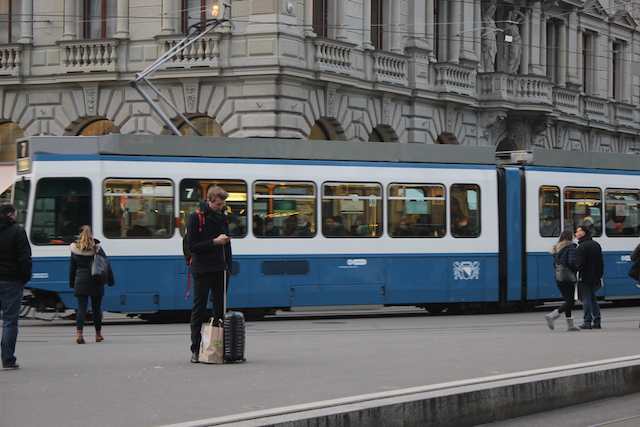
Y este es el código que utiliza YOLOv8 para clasificar la imagen. En particular, vamos a mostrar las 5 principales categorías que estima el modelo que corresponde a la imagen.
from ultralytics import YOLO
import cv2
# Lee la imagen que vamos a procesar
image = cv2.imread('./data/IMG_4121.png')
model = YOLO('yolov8n-cls.pt') # Carga el modelo preentrenado YOLOv8n para clasificación
results = model(image) # Predice lo que hay en la imagen
probs = results[0].probs # Vector con el porcentaje de certeza de las 5 primeras categorías identificadas
# Los nombres de las categorías y las certezas de cada una
top5names = [results[0].names[i] for i in probs.top5]
top5probs = probs.top5conf.cpu().numpy()
print(top5names)
print(top5probs)
Este es el resultado del script
['streetcar', 'trolleybus', 'minibus', 'passenger_car', 'bullet_train']
[ 0.98281 0.015205 0.0015782 0.00015398 0.00012275]
Según YOLOv8, la imagen corresponde en un 98,3% a un 'streetcar', luego, con menor probabilidad a un 'trolleybus', 'minibus', 'passenger_car' y 'bullet_train'.
Para este ejemplo usamos el modelo más pequeño YOLOv8n-cls. Según los requerimientos de tu sistema puedes optar por 5 modelos distintos, donde deberás decidir entre precisión, tiempo de procesamiento y memoria necesaria para ejecutar el modelo.
La siguiente es una tabla de referencia de los 5 modelos de clasificación disponibles y sus rendimientos.
acc top1 y acc top5 son las precisiones medidas en porcentaje de acierto de la primera identificación y las primeras 5 identificaciones respectivamente en el conjunto de validación ImageNet (imágenes de 224x224 píxeles). Las velocidades son medidas en milisegundos.
Detección de objetos
La detección de objetos es la tarea más común en visión por computadora, ya que permite localizar y clasificar objetos en imágenes y videos. Es sumamente útil cuando queremos detectar múltiples objetos en una sola imagen.
Algunos de los casos de uso más comunes son la detección de caras, conteo de personas o seguimiento de vehículos. Pero realizando fine-tuning (tomar un modelo pre-entrenado y ajustarlo a un nuevo conjunto de datos) es posible aplicar este método a la detección de prácticamente cualquier objeto.
La salida de un detector de objetos es un conjunto de cuadros que encierran los objetos de la imagen, junto con etiquetas de clase y puntuaciones de confianza para cada cuadro.
Para la misma imagen de prueba anterior, este es el código para hacer detección de objetos usando YOLOv8
from ultralytics import YOLO
import cv2
# Lee la imagen que vamos a procesar
image = cv2.imread('IMG_4121.png')
model = YOLO('yolov8n.pt') # Carga el modelo preentrenado YOLOv8n para detección de objetos
results = model(image) # Predice lo que hay en la imagen
# Procesa el resultado
for result in results:
boxes = result.boxes # Cajas para cada objeto
result.show() # Despliega en pantalla
result.save(filename='result.jpg') # Guarda en discoEl resultado de esto es el siguiente:

La siguiente es la tabla muestra el desempeño de los 5 modelos de detección de objeto disponibles.
mAPval50-95 es una evaluación sobre el set de validación COCO val2017, que posee imágenes de 640x480 píxeles. La velocidad está medida en milisegundos.
Segmentación semántica
En la segmentación semántica vas un paso más allá de la detección de objetos y consiste en dibujar una máscara alrededor de los objetos que estás detectando, permitiendo saber cuál es su forma o área en la imagen.
Ese nivel de granularidad viene con un costo. En estos modelos, el consumo de memoria y la latencia (tiempo que tienes que esperar para tener el resultado) es más grande que en detección de objetos.
Si quieres hacer uso de este método, asegúrate que el caso de uso lo justifica.
Algunos casos donde requieres este nivel de precisión puede ser en el procesamiento de imágenes médicas o visión para robótica.
La salida de un modelo de segmentación es un conjunto de máscaras o contornos que delinean cada objeto de la imagen, junto con etiquetas de clase y puntuaciones de confianza para cada objeto.
Para realizar la segmentación en nuestra imagen de prueba usando YOLOv8, utiliza el siguiente código:
from ultralytics import YOLO
import cv2
# Lee la imagen que vamos a procesar
image = cv2.imread('IMG_4121.png')
model = YOLO('yolov8n-seg.pt') # Carga el modelo preentrenado YOLOv8n para segmentación
results = model(image) # Predice lo que hay en la imagen
# Procesa el resultado
for result in results:
masks = result.masks # Mascaras del proceso de segmentación
result.show() # Despliega en pantalla
result.save(filename='result.jpg', boxes=False) # Guarda en el discoEl resultado de este proceso es el siguiente:

La siguiente tabla tiene los rendimientos para los 5 modelos disponibles para segmentación semántica.
mAPbox50-95 y mAPmask50-95 son una evaluación sobre el set de validación COCO val2017, que posee imágenes de 640x480 píxeles. La velocidad está medida en milisegundos.
Estimación de puntos clave
La estimación de puntos clave consiste en identificar la ubicación de puntos específicos en una imagen, normalmente relacionados a puntos clave de algún objeto.
Estos puntos clave pueden representar diversas partes del objeto, como articulaciones o puntos de referencia. Estas ubicaciones pueden ser un conjunto de puntos 2D o 3D.
Algunos casos de uso de la estimación de puntos clave puede ser identificar la pose de personas, la pose de las manos o del rostro, con lo que se puede modelar objetos 3D o realizar tracking y analítica en deporte.
La salida de un modelo de estimación de puntos clave es un conjunto de puntos que representan un objeto en la imagen, normalmente junto con las puntuaciones de confianza de cada punto.
YOLOv8 nos permite realizar estimación de pose en personas de la siguiente forma:
from ultralytics import YOLO
import cv2
# Lee la imagen que vamos a procesar
image = cv2.imread('IMG_4121.png')
model = YOLO('yolov8n-pose.pt') # Carga el modelo preentrenado YOLOv8n para estimación de pose
results = model(image) # Predice lo que hay en la imagen
# Procesa el resultado
for result in results:
keypoints = result.keypoints # Puntos clave para estimación de pose
result.show() # Despliega en pantalla
result.save(filename='result.jpg', boxes=False) # Guarda en el discoLa imagen resultante de este proceso es la siguiente:
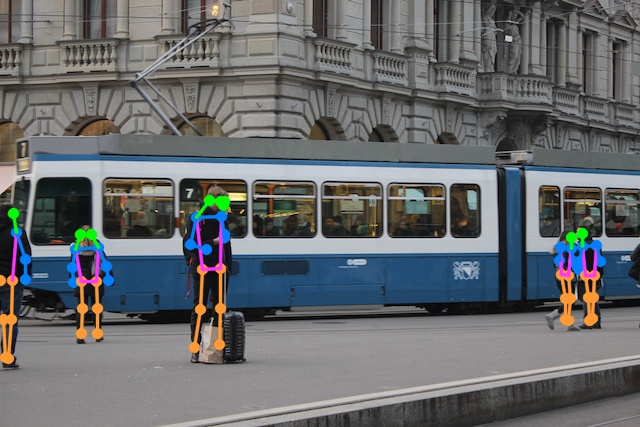
La siguiente tabla tiene los rendimientos para los 5 modelos disponibles para detección de pose.
mAPpose50-95 y mAPpose50 son una evaluación sobre el set de validación COCO val2017, que posee imágenes de 640x480 píxeles. La velocidad está medida en milisegundos.
Conclusiones
En esta publicación te presentamos la visión por computadora en 4 sabores distintos. Puedes copiar los códigos y empezar a jugar desde ahora.
Para determinar el modelo que debes usar en tu proyecto, ten en cuenta los objetivos, requerimientos de precisión y velocidad de procesamiento.
Esto es solo el inicio de cosas más interesantes por ver. Podrías querer ejecutar estos modelos en hardware especializado para tener una cámara en terreno procesando video, o bien entrenar los algoritmos con tu propio set de datos.
Cosas que podemos ver en próximas publicaciones.
Si estás buscando más contenido para iniciarte en Inteligencia Artificial, podrían interesarte las siguientes publicaciones.
 Rodolfo Redlich
Rodolfo Redlich Rodolfo Redlich
Rodolfo Redlich