Preguntas y respuestas a un PDF con chatGPT y LangChain
Te mostramos como usar LangChain y chatGPT para crear un chatbot que responde preguntas sobre el contenido de un PDF


Si chatGPT te sorprendía, cuando le sumes LangChain te va a impactar.
En esta publicación te mostramos como lograr que chatGPT pueda interactuar con el mundo. En particular con un documento PDF.
Con esto esperamos que puedas construir sistemas que puedan hacer tareas más avanzadas que lo que chatGPT podría hacer por separado.
¿Qué es LangChain?
LangChain es una herramienta que puedes usar en conjunto con Large Language Models (LLMs) como chatGPT o Llama2.
Si bien los LLMs pueden realizar tareas genéricas de forma eficiente, se quedan cortas al momento de necesitar una respuesta específica o de un dominio particular.
LangChain te permite conectar LLMs con fuentes de datos e interactuar con el exterior. Te provee interfaces estándar e integraciones para bases de datos, fuentes de texto, ejecución de código en Pandas, entre muchos otros.
En resumen, imagina que le dices a chatGPT que sume 2+2. En vez de dejarle la tarea de sumar a chatGPT, mejor que sepa que debe usar la calculadora, sume 2+2 y te entregue el resultado.
Pero mucha introducción, hagamos un ejemplo
ChatGPT + PDF + LangChain
Usando LangChain, vamos a crear un chatbot con el que puedas interactuar para preguntarle información sobre un PDF.
Este artículo tiene los siguientes pasos:
- Configurar el ambiente de desarrollo
- Entender y usar los Data Loaders de LangChain
- Dividir el documento en piezas
- Usar embeddings para indexar el contenido del PDF
- Chatear con el documento PDF
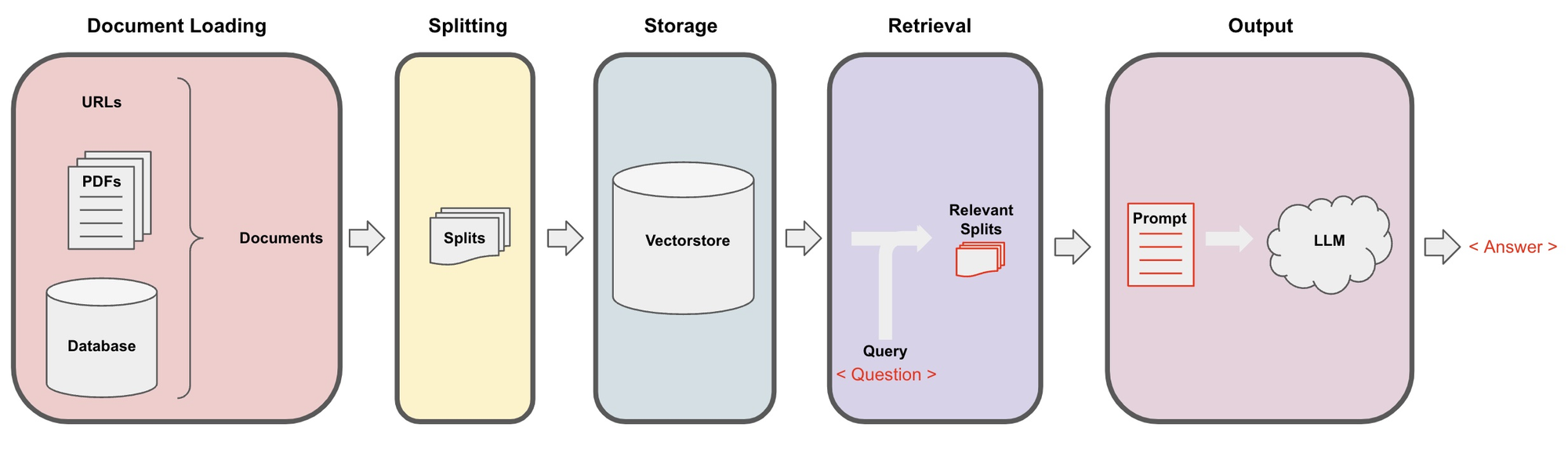
En este caso guardaremos el contenido del PDF en un Vector Store, una base de datos que almacenará el contenido del PDF.
Luego, ante una consulta, vamos a buscar trozos de contenido que podrían responder la pregunta, y estos trozos de texto se entregan dentro de la ventana de contexto en la consulta a chatGPT.
La consulta que genera LangChain para chatGPT se vería algo como esto:
Use the following pieces of context to answer the users question.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
----------------
{context}
{question}Más adelante te cuento como llegamos a ella. Lo importante ahora es que {context} contendrá los trozos de texto del pdf que potencialmente responden a tu pregunta y {question} será la pregunta que le realizas a chatGPT.
TL;DR
Si la ansiedad te la gana y ya te manejas con Python, puedes ver el repositorio con el código de esta publicación, descargarlo y jugar con él.
 rredlich
rredlichConfigurar el ambiente de desarrollo
Asegúrate de tener la versión de python 3.7 o superior. Puedes comprobar la versión de python que tienes instalada con el siguiente comando:
python -VInstala las dependencia necesarias. Ejecuta el siguiente comando para instalar los paquetes para este proyecto:
pip install langchain openai chromadb pymupdf tiktokenChromadb es una base de datos opensource de embedding (lo explicaremos más adelante). Nos permitirá almacenar y entregar trozos de texto que se usarán como contexto en la consulta a chatGPT.
Para analizar el archivo pdf hay varias opciones. Pymupdf es la más rápida, y contiene metadata detallada sobre el PDF y sus páginas.
En nuestro programa importamos las bibliotecas y cargamos la API Key de OpenAI. Esta API Key la puedes conseguir creándote una cuenta como indicamos en este post anterior.
from dotenv import load_dotenv, find_dotenv
import os
from langchain.document_loaders import PyMuPDFLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
load_dotenv(find_dotenv())
api_key = os.environ['OPENAI_API_KEY']Entender y usar los Data Loaders de LangChain
Los LLMs como chatGPT, debido a su capacidad para interpretar texto, son una gran herramienta intermediaria para hacer preguntas sobre el contenido de estos documentos.
Supongamos que tienes texto en un PDF, CSV, una base de datos SQL o una página web. Los Data Loaders son la herramienta que tiene LangChain para conectar estos distintos tipo de documentos con los LLMs como chatGPT.
Hoy nos enfocaremos en el Data Loader PyMuPDFLoader, que esta diseñado para manejar documentos PDF.
En este ejemplo vamos a trabajar con el paper Attention is all you need. Por lo que tenemos que indicar la dirección al pdf, cargar el documento con el Data Loader y cargar su contenido con el comando loader.load().
pdf_path = "./pdfs/NIPS-2017-attention-is-all-you-need-Paper.pdf"
loader = PyMuPDFLoader(pdf_path)
documents = loader.load()Hagamos doble click
documents en este caso tiene el contenido en texto de cada página.
[Document(page_content='Attention Is All You Need\...
Document(page_content='Recurrent models typically...
Document(page_content='Figure 1: The Transformer ...
Document(page_content='Scaled Dot-Product Attenti...
Document(page_content='MultiHead(Q, K, V ) = Conc...
Document(page_content='Table 1: Maximum path leng...
Document(page_content='the input sequence centere...
Document(page_content='Table 2: The Transformer a...
Document(page_content='Table 3: Variations on the...
Document(page_content='References\n[1] Jimmy Lei ...
Document(page_content='[21] Minh-Thang Luong, Hie...Y si por ejemplo consultamos documents[0], tendremos de respuesta el texto de la primera página junto con sus metadatos.
Como ejemplo, estos son los metadatos del PDF disponibles en la primera página:
metadata={
'source': './pdfs/NIPS-2017-attention-is-all-you-need-Paper.pdf',
'file_path': './pdfs/NIPS-2017-attention-is-all-you-need-Paper.pdf',
'page_number': 1,
'total_pages': 11,
'format': 'PDF 1.3',
'title': 'Attention is All you Need',
'author': 'Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, Illia Polosukhin',
'subject': 'Neural Information Processing Systems http://nips.cc/',
'keywords': '',
'creator': '',
'producer': 'PyPDF2',
'creationDate': '',
'modDate': "D:20180212212210-08'00'",
'trapped': ''}Divide el documento en piezas
En esta etapa dividiremos el texto en trozos que pueden ser utilizados por ChatGPT como contexto para responder a una pregunta.
LangChain nos entrega herramientas para esto también, y a grandes rasgos opera de la siguiente forma:
- Divide el texto en trozos pequeños que son semánticamente significativos
- Combina estos trozos pequeños en trozos más grandes hasta alcanzar un tamaño especifico
- Cuando se logra el tamaño, se convierte en una pieza de texto.
- Se continua con un nuevo trozo de texto creando algo de sobreposición para mantener el contexto entre trozos.
Para incorporar el TextSplitter, realizamos lo siguiente:
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=10)
texts = text_splitter.split_documents(documents)Hagamos el doble click
En este caso, el vector texts tendrá todos los trozos de textos, incluyendo metadatos con información de los trozos al final.
[Document(page_content='Attention Is All You Need...
Document(page_content='less time to train. Our m...
Document(page_content='the effort to evaluate th...
Document(page_content='Recurrent models typicall...
Document(page_content='the input or output seque...
...
Document(page_content='[13] Rafal Jozefowicz, Or...
Document(page_content='Zhou, and Yoshua Bengio. ...
Document(page_content='[21] Minh-Thang Luong, Hi...
Document(page_content='[27] Nitish Srivastava, G...
Document(page_content='Macherey, Maxim Krikun, Y...Usar embeddings para indexar el contenido del PDF
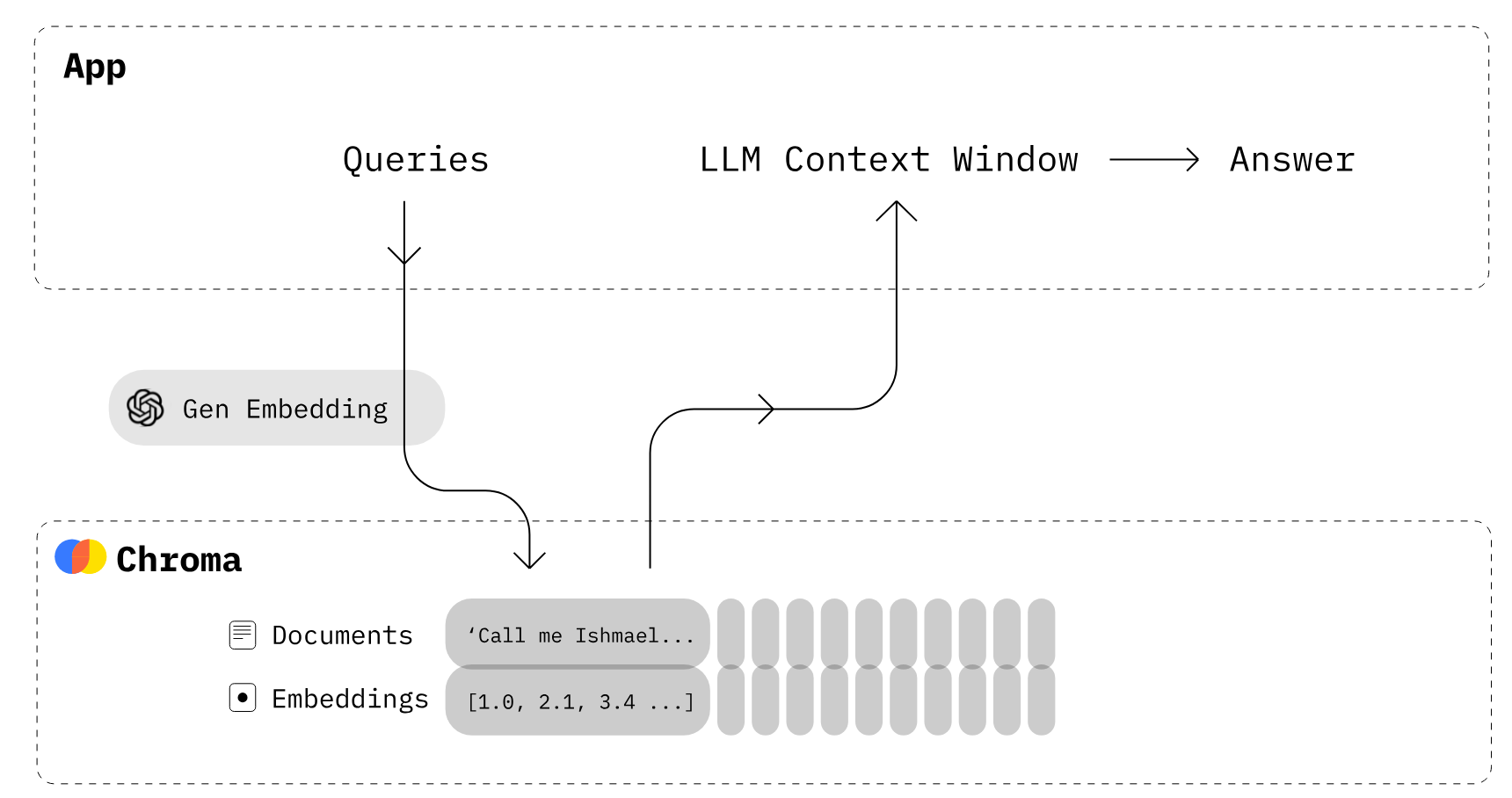
Para poder seleccionar los trozos de texto que queremos agregar como contexto a la consulta, primero tenemos que almacenarlos. La forma más común de hacerlo es calcular vectores de embeddings de cada trozo, almacenar el par de vector y texto en un Vector Store, y usar el vector de embedding para consultar el texto.
Si no sabes que es un embedding, te recomiendo ponerle play al siguiente video antes de continuar con esta publicación.
Al generar los embedings, los trozos de texto se transforman en una representación vectorial. Este vector permite hacer búsquedas semánticas, donde trozos similares de texto pueden ser identificados según qué tan cerca están sus vectores de embedings.
Piénsalo como un buscador de esta forma:
- Escribes una frase
- La frase se convierte a su representación en forma de llave (el vector de embeddings de esa frase)
- Luego se busca en la base de datos la llave que más se le parezca, que no necesariamente es exactamente igual, solo similar semánticamente
- El sistema entrega como respuesta el texto que corresponde a la llave más parecida
Por suerte, para nosotros esta tarea son solo dos comandos
embeddings = OpenAIEmbeddings()
db = Chroma.from_documents(texts, embeddings)
retriever = db.as_retriever()El último comando es un retriever, una interfaz que retorna los trozos de texto ante una consulta. Mastica lo que entrega el Vector Store para entregarlo a la herramienta que lo necesite.
Hagamos el doble click
Como un ejemplo, en este punto podemos consultar por contenido, el que es buscado en la base de datos, y retorna los trozos de texto que más se asimilan a la consulta.
question = "¿Qué hardware utilizaron?"
docs = db.similarity_search(question)Al ver el contenido de docs, podemos ver la respuesta con los 4 textos que semánticamente tienen relación con la pregunta:
[Document(page_content='We trained our models on one machine with 8 NVIDIA P100 GPUs....
Document(page_content='used beam search with a beam size of 4 and length penalty α =...
Document(page_content='from our models and present and discuss examples in the appen...
Document(page_content='Macherey, Maxim Krikun, Yuan Cao, Qin Gao, Klaus Macherey, et...También podemos ver cómo serían los embeddings. Por ejemplo, para el primer trozo de texto tendremos que extraer su contenido y a este calcular los embeddings.
openai_embeddings = embeddings.embed_documents([texts[0].page_content])
print(len(openai_embeddings[0]))
print(openai_embeddings[0][:10])Con esto obtenemos un vector de 1536 elementos, y como ejemplo, podemos visualizar los primeros 10:
1536
[-0.014259453665956193, 0.020836540639615382, 0.03714280766802269, -0.03531432333666023, 0.003034398115983097, 0.03692447956825666, -0.02750914685541417, -0.009251588500663214, 0.0051511421658571414, -0.01833943185782453]Chatear con el documento PDF
Ya llegamos a la última parte, debemos configurar el modelo de chatGPT que vamos a utilizar, y configurar con langChain la consulta que realizaremos.
llm = ChatOpenAI(model_name='gpt-3.5-turbo', temperature=0)
qa = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=retriever)En este caso estamos conectando LangChain con gtp-3.5-turbo usando una temperatura de 0 (baja aleatoriedad en las respuestas de chatGPT) y usaremos el retriever que creamos en el paso anterior, que ya está conectado a nuestra Vector Store con los trozos de texto del PDF.
La ventaja de usar RetrievalQA de LangChain es que no debemos preocuparnos de generar la consulta a chatGPT. Esta herramienta genera el system prompt, anexa el user prompt y agrega los trozos de texto útiles como contexto para responder la pregunta.
Finalmente, hacemos el script para interactuar con la consulta:
print("Realiza una pregunta al documento")
while True:
user_message = input("Pregunta: ")
llm_response = qa(user_message)
print("Respuesta: " + llm_response["result"])Hagamos el doble click
Podemos ver el template que forma el system prompt y el user prompt observando la siguiente variable
qa.combine_documents_chain.llm_chain.prompt.messagesEsto nos arroja una lista de dos elementos, uno para el system prompt y otro para el user prompt. Revisando las variables template en cada uno podemos reconstruir el template con el que estructura la consulta a chatGPT
Use the following pieces of context to answer the users question.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
----------------
{context}
{question}En {context} irán los trozos de texto de contexto y en {question} la pregunta del usuario. Por ejemplo, si la pregunta fuera "¿Qué hardware utilizaron para el entrenamiento?", la consulta que formará LangChain será de la siguiente forma:
Use the following pieces of context to answer the users question.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
----------------
Hardware and Schedule We trained our models on one machine with 8 NVIDIA P100 GPUs. For our base models using the hyperparameters described throughout the paper
We used values of 2.8, 3.7, 6.0 and 9.5 TFLOPS for K80, K40, M40 and P100, respectively.
architectures from the literature. We estimate the number of floating point operations used to train a\nmodel by multiplying the training time, the number of GPUs used
We trained on the standard WMT 2014 English-German dataset consisting of about 4.5 million\nsentence pairs. Sentences were encoded using byte-pair encoding
¿Qué hardware utilizaron para el entrenamiento?Probemos el chat
Y este es el código final. Nuevamente, gracias a las herramientas de LangChain, es un código muy pequeño, con no más de 40 líneas incluyendo un par de comentarios.
from dotenv import load_dotenv, find_dotenv
import os
from langchain.document_loaders import PyMuPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
load_dotenv(find_dotenv())
api_key = os.environ['OPENAI_API_KEY']
# Data Loader
pdf_path = "./pdfs/NIPS-2017-attention-is-all-you-need-Paper.pdf"
loader = PyMuPDFLoader(pdf_path)
documents = loader.load()
# Splitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=10)
texts = text_splitter.split_documents(documents)
# Embeddings
embeddings = OpenAIEmbeddings()
db = Chroma.from_documents(texts, embeddings)
retriever = db.as_retriever()
# Generate
llm = ChatOpenAI(model_name='gpt-3.5-turbo', temperature=0)
qa = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=retriever)
# Asking questions
print("Realiza una pregunta al documento")
while True:
user_message = input("Pregunta: ")
llm_response = qa(user_message)
print("Respuesta: " + llm_response["result"])Ejecutamos el script y ya podemos empezar a conversar con nuestro documento.
Realiza una pregunta al documento
Pregunta: ¿Qué hardware utilizaron para el entrenamiento?
Respuesta: Utilizaron una máquina con 8 GPUs NVIDIA P100.
Pregunta: ¿Cuántos datos utilizaron para entrenar el modelo?
Respuesta: Utilizaron el conjunto de datos estándar WMT 2014 English-German, que consta de aproximadamente 4.5 millones de pares de oraciones.Podemos contrastar esta información con la que aparece en el documento original.

No deja de ser interesante la capacidad de chatGPT de interpretar y responder una pregunta en español desde un texto que está completamente en inglés.
Tareas para la casa
Si quieres empezar a jugar, podrías empezar con las siguientes tareas:
- Considerando que tienes la fuente de los textos de contexto, podrías generar una respuesta que además de mostrar el resultado de chatGPT, muestre las fuentes de información
- También podrías utilizar la información de los metadatos para comunicar al usuario en qué página del PDF se encuentra la información
- Podrías revisar la documentación de LangChain para hacer un ejercicio donde agregues más de un PDF a la base de datos
- Si te gusta el front-end, podrías hacer una interfaz más bonita que la ventana del terminal
¿Tienes consultas sobre esta implementación?
Puedes seguirnos en nuestro perfil en Linkedin, encantados respondemos cualquier duda que puedas tener

Si estás desarrollando con chatGPT, te podrían interesar estas publicaciones
 Rodolfo Redlich
Rodolfo Redlich Rodolfo Redlich
Rodolfo Redlich