Crea imágenes con IA gratis usando Stable Diffusion
Guía introductoria para explorar la IA generativa gratis usando Stable Diffusion. Aprende a correr el modelo, configurar parámetros y a usar la versión SDXL-Turbo para generación de imágenes en un segundo


Seguro has visto imágenes generadas por inteligencias artificial en internet. Las imágenes de Midjourney o DALL-E están por todos lados.
Hoy quiero presentarte la versión open source de los generadores de imágenes, Stable Diffusion.
Esta publicación será una introducción hands-on y al hueso. Enfocado en que puedas correr tu propio generador de imágenes gratis y en menos de 10 minutos. Te mostraré cómo:
- Usar Stable Diffusion
- Configurar un par de parámetros
- Usar la versión más rápida de Stable Diffusion, el recientemente estrenado SDXL-Turbo, pudiendo generar imágenes en menos de un segundo
Si te interesa empezar a probar ahora, entra al Google Colab de esta publicación, cópialo en tu google drive y empieza a jugar.


¿Qué es Stable Diffusion?
Stable Diffusion es un modelo de texto a imagen creado por Stability AI, CompVis y LAION lanzado el 2022.
Es un modelo de latent diffusion, un tipo de red neuronal generativa que iterativamente remueven ruido aleatorio hasta crear una imagen que es guiada por un texto.
El código y los pesos del modelo son open source y pueden correr en GPUs con al menos 4GB VRAM.
El bajo uso de recursos lo hace un match perfecto para Google Colab, un servicio donde podemos subir scripts en python (en particular Jupyter Notebooks) y usar recursos informáticos como GPUs con acceso limitado pero gratuito.
🧑💻 Setup de Google Colab
Si quieres empezar el proyecto en Google Colab desde cero, debes ir a tu Google Drive y crear un nuevo Python Notebook. Para esto anda al menú izquierdo y presiona + Nuevo > Más > Google Colaboratory
Esto generará un nuevo archivo donde tienes que copiar los códigos que te menciono en esta publicación.
Si es tu primera vez con Google Colab, te recomiendo copiar y usar el que te dejé más arriba.
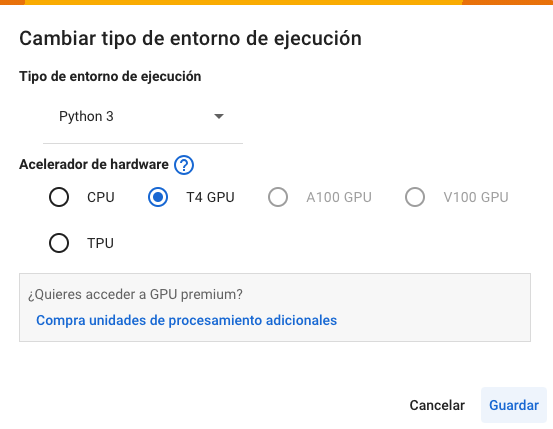
Antes de iniciar la ejecución de tu proyecto, debes asegurarte que el entorno de ejecución te asigne una GPU T4.
Para esto, en el menú superior debes seleccionar Entorno de ejecución > Cambiar tipo de entorno de ejecución y asegurarte de elegir Acelerador de hardware T4 GPU. En el menú desplegable debería verse algo como esto:
🎨 Generemos una imagen con Stable Diffusion
Primero debemos agregar la biblioteca de Diffusers con la siguiente línea de código (si lo haces en tu computador, esto se ejecuta en el terminal)
!pip install diffusers transformers accelerateEn esta publicación usaremos el modelo SDXL-1.0, uno de los últimos modelos que está diseñado para obtener resultados más fotorrealistas y con mejor composición en comparación con los modelos de Stable Diffusion anteriores.
Configurar el modelo de Stable Diffusion solo lleva un par de lineas usando el pipeline DiffusionPipeline.
from diffusers import DiffusionPipeline
import torch
pipe = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0",
torch_dtype=torch.float16,
use_safetensors=True,
variant="fp16"
)
pipe.to("cuda")Con estas lineas hemos configurado todo lo necesario para empezar a generar imágenes:
- Llamamos al modelo
stable-diffusion-xl-base-1.0 - Utilizamos el modelo con precisión
float16para reducir el uso de memoria GPU RAM. Si tienes más recursos, puedes eliminar las variablesrevisionytorch_dtypepara que se ejecute la precisión por defecto defloat32
Ahora estamos listos para generar nuestra primera imagen
prompt = "Fotografía de un gato con lentes de Harry Potter"
image = pipe(prompt).images[0]
# De esta forma muestras la imagen en google colab
image
# De esta otra forma se guarda en el directorio que te ofrece Google
# Puedes verlo en el ícono de la carpeta en el menu izquierdo
image.save(f"gato_con_lentes.png")Deberías ver un resultado similar a este:

🔧 Controlemos algunos parámetros
El código anterior generará una imagen diferente cada vez que lo ejecutes. Si quieres tener salidas determinísticas, puedes usar una semilla en el pipeline. De esta forma te aseguras que siempre tendrás la misma salida
prompt = "Fotografía de un gato con lentes de Harry Potter"
generator = torch.Generator("cuda").manual_seed(42)
image = pipe(prompt, generator=generator).images[0]
Por defecto, las imágenes son de 512x512. Para cambiar el tamaño, tenemos los argumentos height y width. Solo debes asegurarte que los tamaños sean múltiplos de 8.
prompt = "Fotografía de un gato con lentes de Harry Potter"
generator = torch.Generator("cuda").manual_seed(42)
image = pipe(prompt, height=512, width=912, generator=generator).images[0]
Finalmente, el argumento num_inference_steps determina el número de pasos que implementa el algoritmo para generar la imagen. Mientras más pasos, mejores resultados, sin embargo la generación toma más tiempo.
prompt = "Fotografía de un gato con lentes de Harry Potter"
generator = torch.Generator("cuda").manual_seed(42)
image = pipe(prompt, num_inference_steps=25, generator=generator).images[0]Por defecto el número de pasos es 50. Si quieres resultados más rápidos, puedes probar con números más bajos a costa de perder calidad. Un buen equilibrio son 20 pasos.

🚀 ¡Más rápido sin perder calidad! SDXL-Turbo
Hace unos días Stable Diffusion lanzó la versión más rápida del oeste. SDXL-Turbo, capaz de generar imágenes de calidad entre 1 y 4 pasos, tomando menos de 1 segundo.
La buena noticia es que también es muy fácil de usar. Solo debes invocar el modelo sdxl-turbo en el pipeline.
from diffusers import DiffusionPipeline
pipe = DiffusionPipeline.from_pretrained(
"stabilityai/sdxl-turbo",
torch_dtype=torch.float16,
variant="fp16"
)
pipe.to("cuda")Ahora estamos listos para la generación de imágenes. Sin embargo debes considerar las siguientes sutilezas:
- SDXL-Turbo no usa guidance_scale (qué tanto se adhiere la generación de imagen al prompr) o negative_prompts (especificar qué no se quiere generar en la imagen), por lo que hay que deshabilitarlo usando
guidance_scale=0.0 - Se recomienda usar imágenes de
512x512, sin embargo con imágenes más grandes igual funciona - Un solo paso es suficiente para generar imágenes de calidad
prompt = "Fotografía de un gato con lentes de Harry Potter"
generator = torch.Generator("cuda").manual_seed(42)
image = pipe(prompt=prompt, num_inference_steps=4, guidance_scale=0.0, generator=generator).images[0]
image
¡Y eso es todo! Ahora tienes las herramientas generar imágenes con inteligencia artificial gratis a través de Stable Diffusion y Google Colab. Espero que esta guía te sirva y te inspire a explorar nuevas posibilidades creativas.
No dudes en compartirnos tus experiencias, preguntas o creaciones a contacto@zembia.cl 🚀✨
Si estás buscando más contenido para iniciarte en Inteligencia Artificial, podrían interesarte las siguientes publicaciones.
 Rodolfo Redlich
Rodolfo Redlich Rodolfo Redlich
Rodolfo Redlich